2025年中国多模态大模型行业主要模型 主要多模态大模型处理能力表现出色【组图】
行业主要上市公司:阿里巴巴(09988.HK,BABA.US);百度(09888.HK,BIDU.US);腾讯(00700.HK, TCEHY);科大讯飞(002230.SZ);万兴科技(300624.SZ);三六零(601360.SH);昆仑万维(300418.SZ);云从科技(688327.SH);拓尔思(300229.SZ)等
多模态大模型类型及综合对比
视觉+语言的多模态大模型目前主流方法是:借助预训练好的大语言模型和图像编码器,用一个图文特征对齐模块来连接,从而让语言模型理解图像特征并进行更深层的问答推理。这样可以利用已有的大量单模态训练数据训练得到的单模态模型,减少对于高质量图文对数据的依赖,并通过特征对齐、指令微调等方式打通两个模态的表征。

多模态大模型类型-CLIP
CLIP是OpenAI提出的连接图像和文本特征表示的对比学习方法。CLIP是利用文本信息训练一个可以实现zero-shot的视觉模型。利用预训练好的网络去做分类。具体来说,给网络一堆分类标签,比如cat,dog,bird,利用文本编码器得到向量表示。然后分别计算这些标签与图片的余弦相似度;最终相似度最高的标签即是预测的分类结果。论文提到,相比于单纯地给定分类标签,给定一个句子的分类效果更好。比如一种句子模板A photo of a.,后面填入分类标签。这种句子模板叫做 prompt(提示)。句子模板的选择很有讲究,还专门讨论了prompt engineering,测试了好多种类的句子模板。提示信息有多种,下图可以看到它用不同的类别替换一句话中不同的词,形成不同的标签。

多模态大模型类型-Flamingo
Flamingo是一门多模态大型语言模型 (LLM)于 2022年推出。视觉和语言组件的工作原理如下:视觉编码器将图像或视频转换为嵌入(数字列表)。与CLIP不同,Flamingo可以生成文本响应。从简化的角度来看,Flamingo是 CLIP +语言模型,并添加了技术,使语言模型能够根据视觉和文本输入生成文本标记。Flamingo的4个数据集:2个(图像、文本)对数据集、1个(视频、文本)对数据集和1个交错的图像和文本数据集。

多模态大模型类型- BLIP
BLIP(Bootstrapping Language-lmage Pretraining)是由Salesforce在2022年提出的多模态预训练模型,它旨在统一视觉语言任务的理解与生成能力,并通过对噪声数据的处理来提高模型性能口。BLIP的创新主要有两个方面:与CLIP相比,BLIP不仅处理图像和文本的对齐问题,还旨在解决包括图像生成、视觉问答和图像描述等更复杂的任务。BLIP采用了“引导学习”的方式,通过自监督的方式来增强模型对语言和视觉信息的理解。这些特点使其在处理图像和文本数据方面展现了卓越的性能,成为众多领域解决复杂问题的强大工具。

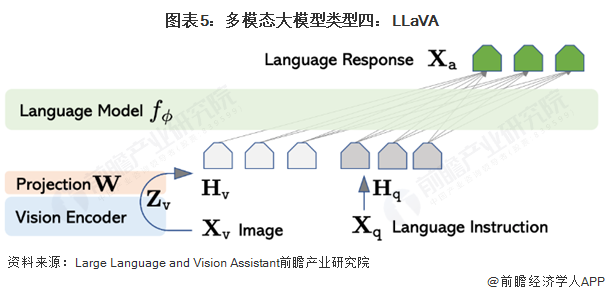
多模态大模型类型-LLaMA
使用视觉编码器CLIP ViT-L/14+语言解码器LLaMA构成多模态大模型,然后使用生成的数据进行指令微调。输入图片X经过与训练好的视觉编码器的到图片特征Z,图片特征Z经过一个映射矩阵W转化为视觉Token H,这样Vison Token Hv与Language Token Hq指令就都在同一个特征空间,拼接后一起输入大模型。这里的映射层W也可以替换为更复杂的网络来提升性能,比如Flamingo中用的gated cross-attentio,BLIP-2中用的Q-former。
更多本行业研究分析详见前瞻产业研究院《全球及中国多模态大模型行业发展前景与投资战略规划分析报告》
同时前瞻产业研究院还提供产业新赛道研究、投资可行性研究、产业规划、园区规划、产业招商、产业图谱、产业大数据、智慧招商系统、行业地位证明、IPO咨询/募投可研、专精特新小巨人申报、十五五规划等解决方案。如需转载引用本篇文章内容,请注明资料来源(前瞻产业研究院)。
更多深度行业分析尽在【前瞻经济学人APP】,还可以与500+经济学家/资深行业研究员交流互动。更多企业数据、企业资讯、企业发展情况尽在【企查猫APP】,性价比最高功能最全的企业查询平台。
前瞻产业研究院 - 深度报告 REPORTS

本报告前瞻性、适时性地对多模态大模型行业的发展背景、供需情况、市场规模、竞争格局等行业现状进行分析,并结合多年来多模态大模型行业发展轨迹及实践经验,对多模态大...
如在招股说明书、公司年度报告中引用本篇文章数据,请联系前瞻产业研究院,联系电话:400-068-7188。
品牌、内容合作请点这里:寻求合作 ››


前瞻经济学人
专注于中国各行业市场分析、未来发展趋势等。扫一扫立即关注。
前瞻产业研究院
中国产业咨询领导者,专业提供产业规划、产业申报、产业升级转型、产业园区规划、可行性报告等领域解决方案,扫一扫关注。相关阅读RELEVANT



























